Agent-Hypervisors
Audience: Engineers and researchers interested in the future of autonomous AI.
Reading time: ~10 minutes.
Where the puck is going
As of mid-2025, there is a Cambrian explosion of AI agent frameworks (LangChain, LlamaIndex, AutoGPT, CrewAI, and dozens more). These tools aim to orchestrate language models with business workflows, stitching together data retrieval, tool invocation, memory, and evaluation loops into self-directed agents that can plan, act, and refine their own strategies while meeting real-world constraints such as latency, cost, compliance, and observability.
Good stuff, to be sure. But paradoxically, as of this writing it is hard to point to real killer apps outside of call center automation and coding assistance, while at the same time there are tons of excellent-but-hard-to-differentiate tools and frameworks. This will probably sort itself out as companies attack vertical domains and start to generate value (becoming the Salesforce of supply-chain logistics or what have you).
But what happens next as this tech matures?
Some things are pretty obvious:
- Continual improvement in both OSS and frontier language models.
- Steadily falling inference costs from new silicon and optimization tricks.
- Ever-wider context windows that let agents reason over whole corpora instead of snippets.
- Plug-and-play connectors to the enterprise data stack (vector stores, event streams, ERP APIs).
- AgentOps guard-rails (versioning, canary tests, automated roll-backs) becoming first-class citizens in every framework.
All of these will advance the ongoing deep learning revolution and ultimately propel agentic AI from niche experiments to the default operating layer for every modern workflow.
What’s less apparent is the next step: the advent of what I’m calling “agent-hypervisors”.
What are agent-hypervisors?
Simply put, agent-hypervisors are systems that design, deploy, monitor, and, most importantly, learn to optimize entire fleets of LLM agents.
A “hypervisor” is software that allows a single physical machine to host multiple virtual machines. The hypervisor’s job is resource allocation, isolation, and scheduling: it decides which VM gets CPU time, how memory is partitioned, and how to keep workloads from interfering with each other. The VMs themselves have no visibility into these decisions.
An agent-hypervisor plays an analogous role for AI agent fleets. It allocates compute, schedules work, isolates failure domains, and governs the multiple layers of services that together solve a complex task. The critical difference is that a traditional hypervisor follows static rules, while an agent-hypervisor learns its scheduling and allocation strategies from the fleet’s own telemetry.
This isn’t entirely a new idea, but taken to its logical conclusion, agent-hypervisors open the door to brand-new capabilities that are presently impossible. Precursors to agent-hypervisors include three-plane architectures and AgentOps approaches.
Three-plane architectures
Many AI stacks are moving toward layered architectures, and have elements of logical separation similar to cloud applications (but replace the base data plane with an agent “execution” plane).
- Control plane - allocation of where things run, CPU/GPU provisioning, rolling out updates, monitoring costs & drift, and potentially automatically spawning execution agents on demand.
- Orchestration plane - business logic, explicit graphs/flows, shared resources (memory, Kubernetes clusters), retries, tool routing, and evaluation hooks.
- Execution plane - single agents or agent chains that use LLMs and tools (web search, database access). This layer is similar to LangChain and CrewAI’s current focus.
AgentOps
AgentOps is a practice and set of tools for deploying, testing, monitoring, and continuous improvement of AI agents, similar to how DevOps supports distributed systems and services and how MLOps supports ML model lifecycle management.
The goal of AgentOps is to manage the deployment & rollout of AI agents similar to DevOps, with an additional focus on governance and guard-rails, cost and performance optimization (particularly when 3rd-party APIs are being used), and observability and traceability.
Care and feeding of agent-hypervisors
Language-model agents are typically stochastic, self-modifying, and multi-step (and in many cases also multimodal). Traditional DevOps assumes deterministic code. MLOps rarely has to track hundreds of tool calls, chain-of-thought traces, or dynamically generated sub-agents. Without a specialized operational stack, teams may struggle to answer basic questions such as “Why did the agent choose that action? How much did that incident cost? When did performance regress?”
The insight of agent-hypervisors is that we can create an AI agent to “manage” the business logic (orchestration plane) and resource allocation (control plane) simultaneously, and to learn the characteristics of the overall system. This signal in turn allows further training and refinement of the agent-hypervisor model and system itself, and as a result leads to self-optimization of design, deployment, and monitoring of the fleet of agents and attendant business logic.
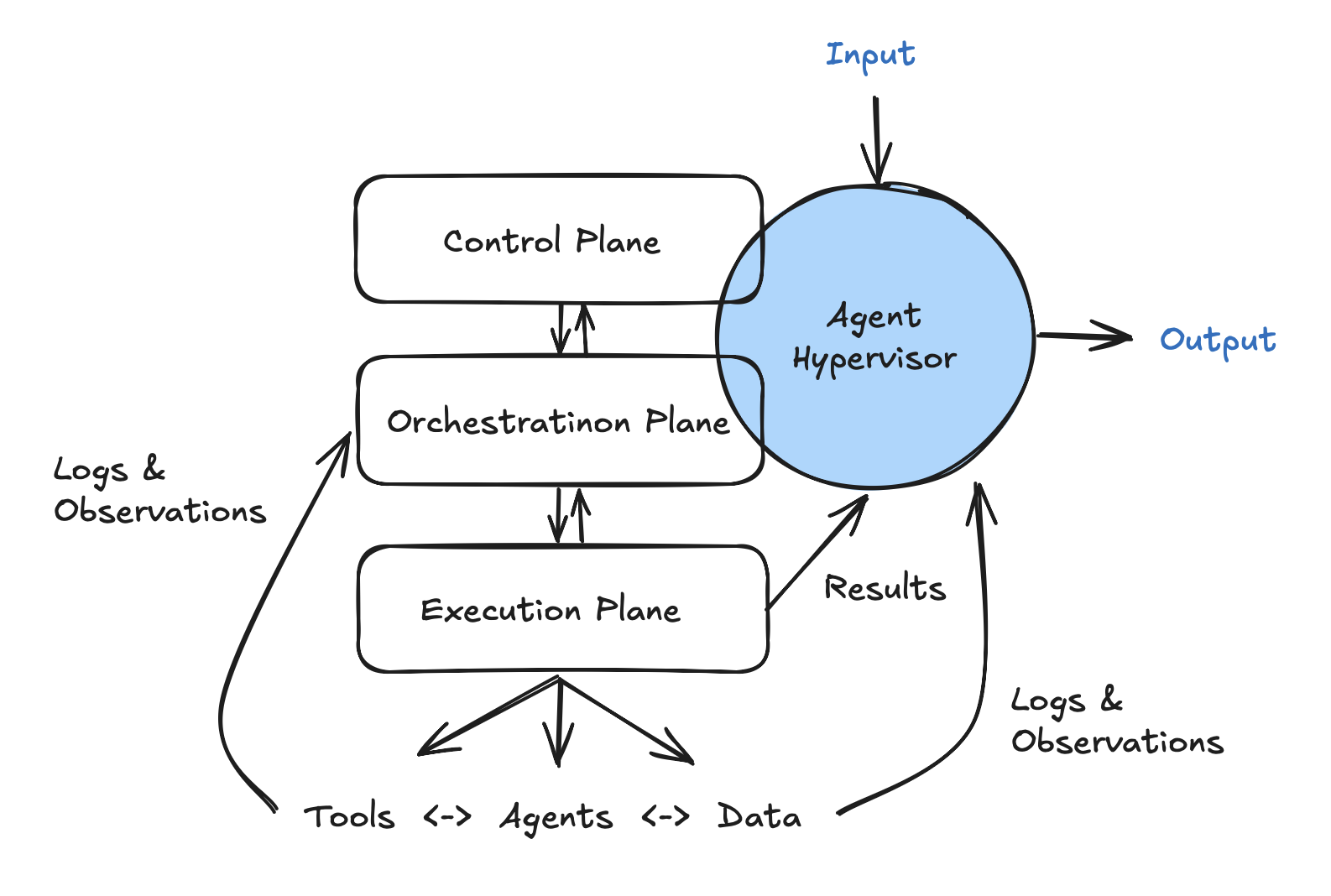
In this simplified diagram, you can see input/output flowing through the agent-hypervisor, but this isn’t an actual constraint. For basic workflows, this is probably a good pattern, but for more complex solutions there will be numerous inputs and outputs occurring at the execution plane (for example, agent access to databases and report generation for business decision makers). The choice to coalesce that flow through the agent-hypervisor, or not, is a systems design decision; the important part is that results, logs, and telemetry signals need to be fed to the agent-hypervisor for learning and self-optimization to occur.
Data for agent-hypervisor training and tuning
Putting a learning agent above the control plane is plausible because the tasks there are heavily meta – planning, scheduling, capacity management – and reward signals are usually available (latency, financial cost, success rate).
Expanding the role of the agent-hypervisor to the orchestration plane and allowing it to design and refine tasks including business logic, tool routing, and utilization of shared resources is more difficult, but properly constrained it is also data-rich and the outputs are measurable (and therefore trainable).
The critical point is that the objectives are measurable, which means the optimization is tractable. A simplified reward signal might look like this:
Where each term is normalized to a common scale, and the weights reflect business priorities. Success and compliance are rewards; latency and cost are penalties. A production system would need additional terms (output quality distinct from binary success, an exploration bonus to prevent premature convergence on suboptimal configurations), and the linear scalarization shown here can only find solutions on the convex hull of the Pareto front. The exact formulation matters less than the principle: if you can measure it, a learning system can optimize against it.
The weights are the human’s lever. By adjusting w₁…w₄, you steer the system toward “fast but expensive,” “cheap but slower,” or “strictly policy-compliant.” The hypervisor evaluates candidate configurations against this signal and selects the one with the highest R. Over time, it learns which configurations perform well under which conditions, and this is where agent-hypervisors diverge from static orchestration: they do not just execute a plan, they learn to plan better.
Implementation approaches (as of 2025)
How does the hypervisor learn? As of this writing, two approaches seem viable. The first is parameter-efficient fine-tuning (LoRA or similar), training the hypervisor model directly on telemetry from the fleet. This produces a specialized model but requires managing a train/deploy loop in production. The second is in-context learning, where the hypervisor absorbs fleet telemetry as few-shot examples within a long context window, learning patterns without explicit training. This eliminates training-time hysteresis and allows rapid iteration across multiple frontier models.
The honest answer is that the implementation technique matters less than the data. A hypervisor that has access to rich, structured telemetry from every agent in the fleet can learn from it regardless of the learning mechanism. The telemetry is the curriculum. The technique is a detail that will evolve with the models.
Staging agent-hypervisors in real-world systems
Rolling out an agent-hypervisor is probably best thought of as a journey. Each stage adds a carefully bounded slice of autonomy, proves out new feedback signals, and hardens the operational scaffolding before the next capability is unlocked.
v1 - Observe, enforce & schedule
Read-only visibility into every running agent, enforcement of static guard-rails, and basic resource scheduling (maybe limited to cost ceilings). The hypervisor does not rewrite workflows; it only decides when and where they should execute.
v2 - Controlled self-optimization
The hypervisor can propose micro-optimizations like tool-ordering changes and memory window sizes, and deploy them behind feature flags. A human operator (or an offline evaluator) must sign off before changes hit production.
v3 - Autonomous graph refactor & agent synthesis
The hypervisor is trusted to rewrite entire DAGs, spin up ad hoc sub-agents, and retire obsolete ones, subject only to guard-rails expressed as high-level policies (budget, compliance boundaries).
v4 - Beyond human patterns
This is where it gets interesting, and where the implications become difficult to reason about. I develop this below.
Graduating from one stage to the next will require multiple steps, including:
- Telemetry completeness audit Confirm that every tool call, LLM token stream, and environment variable flows into your tracing store, with schema contracts and retention policies.
- Reward-function validation Simulate dozens of historical runs and verify that the computed reward ranks outcomes in the same order a domain expert would.
- Safety harness burn-in
- Canary + rollback proven in chaos tests
- Budget governor rejects at least one simulated runaway scenario
- Policy-violation detector catches seeded infractions (prompt leaks, PII exfiltration).
- Human reviewer capacity check Measure whether human reviewers can keep pace with the system’s output cadence without becoming a bottleneck. If approval latency constrains throughput, invest in reviewer tooling or advance to partial autonomy.
Beyond human patterns
Stages v1 through v3 are engineering problems. Hard ones, but recognizable: better monitoring, smarter scheduling, automated refactoring of agent graphs. A competent infrastructure team could build toward any of them today. Stage v4 is different in kind, not just in degree.
When AlphaGo played Move 37 in its second game against Lee Sedol, every professional Go player watching thought it was a mistake. The move violated established patterns, placing a stone where no human master would. It won the game. Move 37 was not a fluke. It was the product of a system that had learned to optimize for winning without any constraint to play in ways humans would recognize as good Go. The system found a region of the strategy space that human experts had never explored, not because they lacked the skill, but because their intuitions actively steered them away from it.
Agent-hypervisors at the v4 stage will produce something analogous in software architecture. A hypervisor optimizing against a reward function that balances success, latency, cost, and compliance has no reason to produce architectures that map to microservices, event-driven pipelines, or any other pattern humans designed for human understanding. It will produce whatever configuration maximizes the reward. If routing certain requests through three redundant agents with contradictory system prompts and taking a majority vote produces better outcomes than a clean single-agent pipeline, the hypervisor will learn that pattern. If dynamically spawning and destroying sub-agents on a millisecond timescale outperforms static agent pools, it will learn that too. These patterns will not be documented in any systems design textbook because no human would design them.
There is a recurring pattern in AI research: hand-designed domain knowledge works well initially, and then general methods leveraging raw computation surpass it. The hand-designed patterns (three-plane architectures, static DAGs, orchestration graphs) are the domain-specific knowledge of infrastructure engineering. They matter, at stages v1 through v3. And then computation catches up. A learning hypervisor with enough telemetry and enough optimization pressure will discover configurations that outperform anything a human architect would design, for the same reason that AlphaGo discovered moves that outperform anything a human Go master would play.
The implications cut in two directions. The optimistic read: agent fleets that self-optimize against measurable objectives will find efficiencies that are currently invisible to us, in the same way that neural architecture search discovered network topologies that no researcher would have proposed. The uncomfortable read: these systems may completely sacrifice human legibility. You cannot debug an architecture you do not understand. The observability problem, which is manageable at v1 through v3, becomes existential at v4. If the system works but nobody can explain why, what happens when it stops working?
This is why the staging matters. The graduation criteria (telemetry audits, reward validation, safety harness burn-in) are not bureaucratic checkboxes. They are the mechanism by which we build enough understanding of the system’s behavior at each stage to survive the loss of understanding at the next. By the time a hypervisor reaches v4, the monitoring, the reward validation, and the circuit breakers need to be robust enough to govern a system whose internal logic is opaque. That is a hard problem. It is also, I believe, an inevitable one.
Conclusion
The near-term path for agent-hypervisors is clear: better telemetry, learned scheduling, automated graph optimization. These are valuable and buildable today. But the reason to think about agent-hypervisors now, before the infrastructure fully exists, is the end-state they point toward. Self-optimizing agent fleets will eventually produce computational patterns that no human would design, patterns optimized for performance rather than legibility. The question is not whether this will happen. Given enough compute and a measurable reward signal, it is a mathematical inevitability. The question is whether we will have built the safety infrastructure to govern systems we can no longer read. That work starts at v1.